| 90 |
| �� ���⣺ ��Ӧ:������ҳ��Ŀ��Ϣ�ɼ���ʦ3.0�汾 �����ɼ� ץȡ ������ҳ��Ϣʾ�� |
| �� ���ݣ� | 11¥ |
���岽���趨��ҳ�Զ���ҳ��ʽ ������飬�����ҳ���Ե�����۵ײ���С�����Ψ����з�ҳ������֮�⣬��ַ��û��ҳ������Ҳû�п�������ҳ��ת����ť������ֻ�ܴӴ������������ˣ����ǿ��Ը��ƴ��������ٵ�FRONTPAGE������ճ�������˲���Դ�룬Ҳ���Ե����ҳ�Ҽ����鿴Դ�룬���Կ�������һ�����ӣ�������nextpage�����������������������nextpage�� 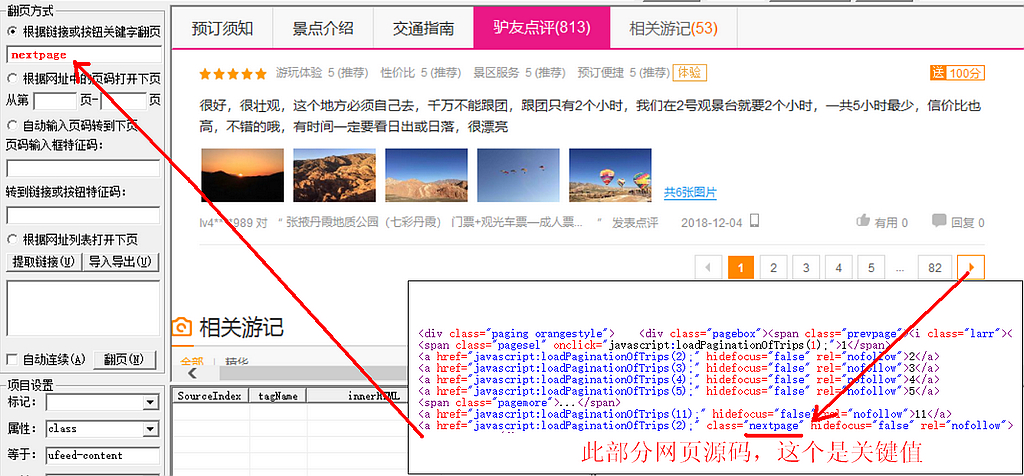 |
���� |
| �� ���ֶ��뱳���� �� postulate vt.Ҫ�ٶ������� |
| �� ����ʱ�䣺2019-3-22��16:18:21 | |�ظ�|����| |