
| 90 |
| □ 主题: 本站最新力作--网页文本采集大师 发布了 |
| □ 内容: | 1楼 |
网络信息时代,天天上网,经常会遇到喜欢的文章,或者是小说等,小则一两页,多则几十页,甚至上百页、上千页,这么多文字,要复制下载就显得非常的麻烦,本来要频繁的在记事本和网页浏览器上切换就已经够难过的了,现在还面临着要同时做这种枯燥的机械的动作几十次、几百次的问题,到底有没有更简单、高效、省力的办法呢? 呵呵,算你找对地方了,我们开发的“网页文本采集大师”就是这么一款专门为你准备的工具软件。 网页文本采集大师是一款专门用于批量采集、复制或者说是下载网络上的文章或者是小说,甚至是整个网站文字内容的工具,不管是静态的网站,还是动态的网站,只要有文字,它都能够获取,只要输入简单的几条信息,就可自动批量为你下载复制网络文章了,可谓是轻松快捷。 除了抓取网上的文章,你还可以用它来抓取一些特殊的信息,比如抓取百度词典上的信息,或者你也可以用它抓取一些网页上的链接地址。 另外本软件还具有很多其它的功能,比如文本段落重排、文本合并、文件批量改名等功能,非常实用,要知道时间就是生命,可以让电脑为你工作的事,你千万不要自己去做,快下载用用看吧,希望你会喜欢上她。 软件下载地址:gwtsetup.exe 软件大小:909KB 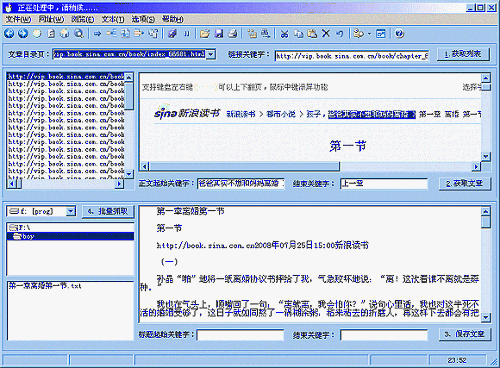 |
―― |
| □ 争分夺秒背单词 → vex vt.使烦恼,使恼火 |
| □ 发帖时间:2009-6-1|1:05:02 | |回复|返回| |