��һ�������ǵ�����ȡ����������Ŀ¼���ӣ����ǿ����ȸ��Ʋ�ͬλ�õ��������ӣ�����������·��Ķ࣬��Ŀ¼����62ҳ�����Ǿ����ڲ�ͬҳ�и����������ӣ�����һ����һ�£�
http://blog.sina.com.cn/s/blog_69f9326d0102ycv7.html
http://blog.sina.com.cn/s/blog_69f9326d0102ycrq.html
http://blog.sina.com.cn/s/blog_69f9326d0102xqns.html
�������Dz��ѷ��֣������������µ����ӣ�ǰ��һ���ֶ��ǣ�
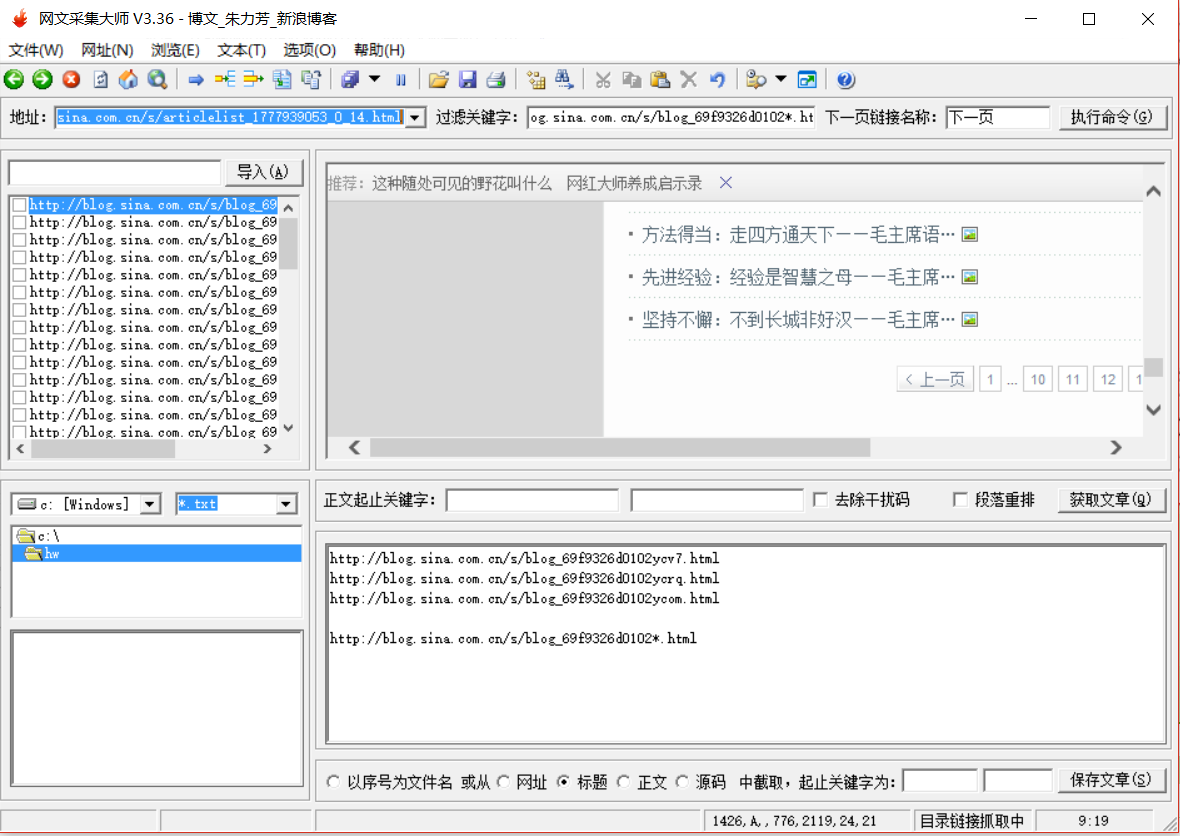
http://blog.sina.com.cn/s/blog_69f9326d0102
�ã����Ǿ��������е�����ַ���Ϊ�ؼ��֣���������ַ������Ҳ�Ĺ��˹ؼ��������룺
http://blog.sina.com.cn/s/blog_69f9326d0102*.html
�����*��ͨ��������Դ���1����������ַ��������.html�Dz������ӵ���չ������������Ҳ���ԣ���������ȡ�ؼ��֣���һ��Ҫȡ����ѧ�еĶ���������Լ����
�����˹��˹ؼ��֣���������������һҳ���ӹؼ��֣���һ�£�����ҳ�����һҳ���Ӿ�����һҳ������ֱ���ڴ������������һҳ���ɣ������꣬�ٵ��ִ������ڵ����˵��е����ȡĿ¼���Ӽ��ɣ�����ͻῪʼ�Զ���������ȥ��ȡ���������ˣ�ֱ��62ҳ����ȫ����ȡ��ϡ�
|